
판다스의 자료 구조(1) - 데이터의 유형
업데이트:
엑셀 데이터를 파이썬으로 가져오자
지난 포스팅에서는 직장인들이 엑셀 작업을 좀 더 효율적으로 해낼 수 있도록 도와주는 파이썬 판다스(pandas) 라이브러리에 대해 간단히 소개했다. 이제 본격적으로 판다스의 자료구조를 살펴보고, 엑셀 자료를 파이썬으로 가져오는 방법을 살펴보도록 하자.
데이터의 유형 구분하기
1차원 데이터와 2차원 데이터
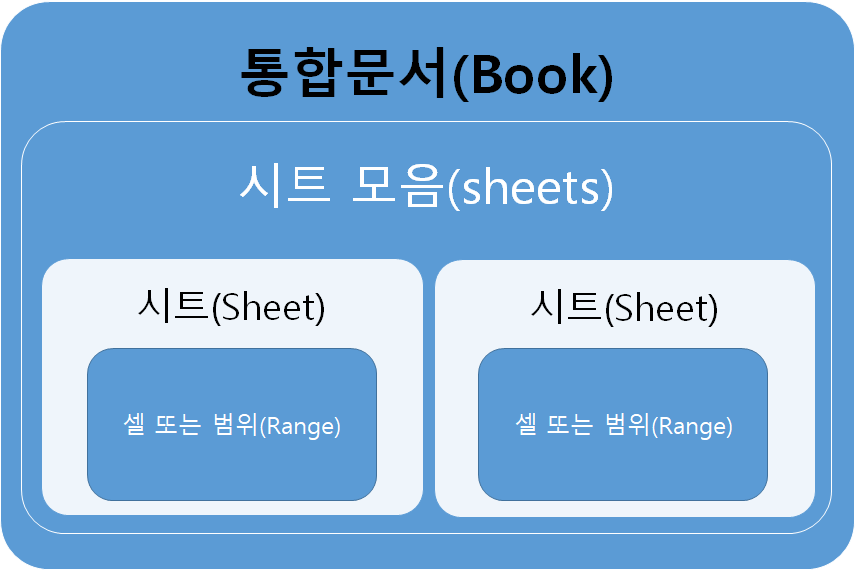
우리가 업무적으로 접하는 데이터들의 구조는 대부분 2차원으로 되어 있다. 2차원 데이터란 여러개의 행(row, 가로줄)과 열(column, 세로줄)로 이뤄진 표 또는 행렬 형식의 자료를 말한다. 쉽게 말하자면 하나의 엑셀 시트에 담겨있는 표가 곧 2차원 데이터다. 1차원 데이터는 하나의 행 또는 하나의 열로 이뤄진 배열 또는 벡터 형식의 자료이다. 2차원에서 가로나 세로 방향으로 한줄을 뽑아내면 1차원 데이터가 된다. 아래의 엑셀 자료 중 왼쪽은 1차원 데이터, 오른쪽은 2차원 데이터를 보여주고 있다. 회색 부분은 각 행 또는 열의 이름이고, 흰색 부분이 데이터에 해당한다.
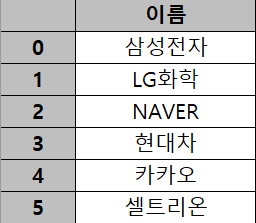 |
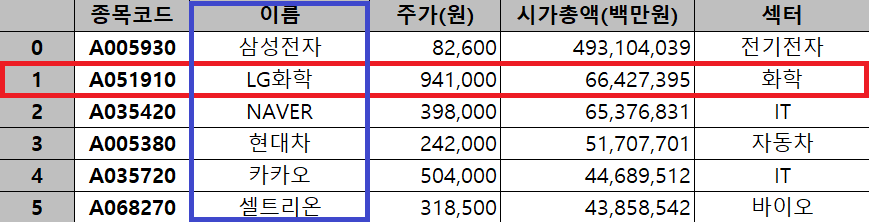 |
|---|---|
| 1차원 자료 | 2차원 자료 |
횡단면 데이터와 시계열 데이터
2차원 데이터 유형은 크게 횡단면(cross-section) 데이터와 시계열(time-series) 데이터로 구분된다. 횡단면은 하나의 시점(또는 기간)에 관측된 여러 대상의 다양한 특성을 보여주는 자료를 말한다. 반면 시계열은 여러 시점(또는 기간)에 관측된 여러 대상 혹은 특성들을 비교하는 자료를 말한다.
횡단면과 시계열 데이터의 행과 열의 구성요소는 일반적으로 다음과 같다.
| 구분 | 횡단면 | 시계열 |
|---|---|---|
| 행 | 관측 대상 | 관측 시점 |
| 열 | 특성 | 특성 또는 대상 |
횡단면 데이터의 행은 사람, 기업, 상품, 국가 등의 관측 대상, 열은 그들의 다양한 특성들로 이뤄진다. 위에서 봤던 2차원 데이터 예시는 특정시점의 6개 관측 대상(행 - 삼성전자 등)에 대한 5개 특성(열 - 주가, 섹터 등)을 보여주는 횡단면 데이터에 해당한다.
시계열의 데이터의 행은 용어 그대로 날짜/시간의 연속된 흐름, 열은 다양한 특성 또는 관측 대상들로 구성된다. 아래의 첫번째 예시는 5개 시점(행 - ‘21.3.8 ~ 3.12)에 관측한 삼성전자의 3개 특성(열 - 주가, 시가총액 등)을 보여준다. 두번째 예시는 같은 기간(행)에 관측한 3개 대상(열 - 삼성전자 등)의 주가 변화를 보여준다.
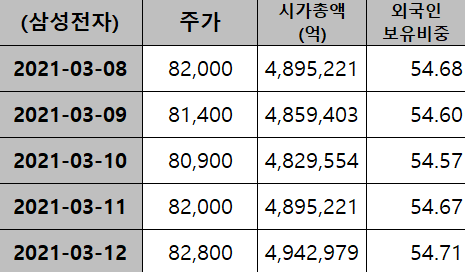 |
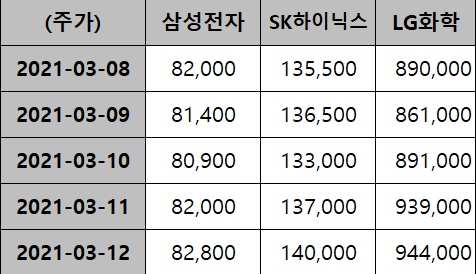 |
|---|---|
| 시계열 자료 예시(1) | 시계열 자료 예시(2) |
횡단면과 시계열을 근본적으로 나누는 것은 결국 행(row)의 특성이다. 횡단면 자료에서 행은 대부분 순서가 중요하지 않다. 따라서 행의 구분은 보통 임의의 기준에 따라 일련번호를 붙이는 방식이다. 반면, 시계열 자료에서 행은 곧 시간이기 때문에 순서가 매우 중요하고, 임의로 뒤바꿀수 없다.
당분간 판다스의 문법을 익히기 위한 예시들은 횡단면 자료를 사용할 것이다. 시계열 자료는 고유한 전처리 방식이 있기 때문에, 판다스 기초를 익힌 이후 별도 포스팅할 예정이다.
pd.read_excel 함수
앞에서 횡단면 데이터의 예시로 들었던 6개 주식 종목의 주가, 시가총액 등의 자료를 파이썬으로 불러와보자. 우선 주식 종목 리스트가 담긴 엑셀파일(내려받기)을 내려받은 뒤, 같은 폴더에 노트북(.ipynb) 파일을 새로 만들어 다음과 같이 입력하자.
1 import pandas as pd
2
3 df = pd.read_excel('주식_종목_리스트.xlsx',index_col='종목코드')
4 df
[코드설명]
line 1 : 판다스 라이브러리를 pd 라는 약어로 불러온다.
line 3 : 판다스의read_excel함수를 사용해 주식_종목_리스트.xlsx에 담긴 표를 가져와 변수df에 할당한다.index_col=는 (뒤에서 설명할) ‘인덱스’로 사용될 열의 이름을 지정하는 옵션(파라메터)이다.
line 4 : 변수 df를 출력한다.
| 종목명 | 주가(원) | 시가총액(백만원) | 섹터 | |
|---|---|---|---|---|
| 종목코드 | ||||
| A005930 | 삼성전자 | 82600 | 493104039 | 전기전자 |
| A051910 | LG화학 | 941000 | 66427395 | 화학 |
| A035420 | NAVER | 398000 | 65376831 | IT |
| A005380 | 현대차 | 242000 | 51707701 | 자동차 |
| A035720 | 카카오 | 504000 | 44689512 | IT |
| A068270 | 셀트리온 | 318500 | 43858542 | 바이오 |
엑셀파일에 있던 2차원 데이터를 변수명 df의 파이썬 객체로 불러왔다. 판다스 라이브러리에서 2차원 데이터를 담는 객체를 데이터프레임(DataFrame)이라고 한다. 즉, pd.read_excel 함수는 엑셀의 표를 데이터프레임으로 가져오는 역할을 한다.
결과로 출력된 데이터프레임의 모습을 보면 왼쪽과 위쪽에 굵은 글씨로 된 이름들이 한줄 씩 붙어있다. 왼쪽의 것을 인덱스(index), 위쪽의 것을 컬럼명(columns) 이라고 한다. 인덱스와 컬럼명 사이에 있는 표의 내용들을 자료값(values) 이라고 한다. 이렇게 2차원 데이터를 3가지 구성요소(인덱스, 컬럼명, 자료값)로 나타내는 것이 판다스 데이터프레임 객체의 주요 특징이다.
이제 df 객체에서 1차원 데이터만 뽑아내보자
1 sr = df['종목명']
2 sr
[코드설명]
line 1 : 데이터프레임 df 에서 ‘종목명’이라는 이름의 열을 추출해 sr 변수에 할당한다.
line 2 : 변수 sr을 출력한다.
종목코드
A005930 삼성전자
A051910 LG화학
A035420 NAVER
A005380 현대차
A035720 카카오
A068270 셀트리온
Name: 종목명, dtype: object
2차원 데이터프레임에서 하나의 열을 뽑아 1차원 데이터를 만들었다. 판다스 라이브러리에서 1차원 데이터를 담는 객체를 시리즈(Series)라고 한다. 출력된 결과를 보면, 데이터프레임과 달리 시리즈는 컬럼명이 없고 인덱스와 자료값 만으로 구성되어 있다.
엑셀의 표를 가공해서 만든 데이터프레임과 시리즈는 판다스의 핵심이 되는 자료형이다. 이 2가지 자료형이 갖는 기능을 익히는 것만으로도 엑셀 업무의 상당 부분을 대체할 수 있다.
댓글남기기