
DRM 걸린 엑셀 파일을 판다스 데이터프레임으로 불러오기
업데이트:
이전글 : xlwings의 Book, Sheet, Range 객체 다루기
엑셀의 표를 Series / DataFrame 객체로 변환하기
지난 포스팅에서 xlwings로 생성한 Range 객체의 value 속성을 통해서 엑셀 파일에 담긴 자료들을 파이썬으로 가져오는 과정을 살펴봤다. 이 경우 자료값들은 파이썬의 ‘리스트’ 또는 ‘리스트 of 리스트’ 형태를 취하게 된다. 이를 판다스의 시리즈나 데이터프레임 객체로 변환하려면, 인덱스와 컬럼명을 별도로 지정해줘야 하는 불편함이 있다. 다행히 xlwings에서는 Range 객체를 곧바로 시리즈/데이터프레임으로 변환하는 기능이 존재한다.
Range 객체의 형태변환 : options 메서드
이전 포스팅에서의 실습을 이어나가보자. 먼저, 첫번째 시트(sh1)에 종목코드와 종목명이 있는 범위(A1:B7)를 다음과 같은 방법을 통해 딕셔너리 자료형으로 변환할 수 있다.
dtn = sh1['A2:B7'].options(dict).value
dtn
{'A005930': '삼성전자',
'A051910': 'LG화학',
'A035420': 'NAVER',
'A005380': '현대차',
'A035720': '카카오',
'A068270': '셀트리온'}
위와 같이 엑셀의 특정 범위를 Range 객체로 만든 다음, .options(자료형이름).value를 붙여주면 지정한 자료형에 따라
값을 반환한다. 자료형 이름으로 dict를 입력하면 해당 범위의 첫번째 열을 키(key), 나머지 열을 값(value)으로 갖는
딕셔너리를 반환한다. (이미 확인했듯이 options 메서드를 거치지 않고 바로 .value를 붙이면 리스트 자료형으로 반환된다.)
판다스의 시리즈/데이터프레임 객체로 변환하는 것도 같은 방법으로 가능하다. 먼저 판다스 라이브러리를 import 하고(약칭 pd), 자료형 이름에 pd.Series(1차원 자료) 또는 pd.DataFrame(2차원 자료)을 입력하면 된다.
import pandas as pd
sr = sh1['A1:B7'].options(pd.Series).value
sr
종목코드
A005930 삼성전자
A051910 LG화학
A035420 NAVER
A005380 현대차
A035720 카카오
A068270 셀트리온
Name: 종목명, dtype: object
df = sh1['A1:E7'].options(pd.DataFrame).value
df
| 종목명 | 주가(원) | 시가총액(백만원) | 섹터 | |
|---|---|---|---|---|
| 종목코드 | ||||
| A005930 | 삼성전자 | 82600.0 | 493104039.0 | 전기전자 |
| A051910 | LG화학 | 941000.0 | 66427395.0 | 화학 |
| A035420 | NAVER | 398000.0 | 65376831.0 | IT |
| A005380 | 현대차 | 242000.0 | 51707701.0 | 자동차 |
| A035720 | 카카오 | 504000.0 | 44689512.0 | IT |
| A068270 | 셀트리온 | 318500.0 | 43858542.0 | 바이오 |
엑셀 범위에서 기본적으로 첫번째 열이 인덱스(index), 첫번째 행이 컬럼명(columns)으로 지정된다.
Range 확장하기 : expand 매개변수
다음과 같은 상황을 가정해보자. 당신은 매일 사내 업무시스템의 특정 화면에서 자료를 내려받아서 일일 보고를 위한
데이터 산출 작업을 하고 있다. 지금까지 실습했던 주식_종목_리스트.xlsx 파일과 컬럼명은 동일하지만,
아래 그림과 같이 매일 종목의 종류와 수만 바뀐다고 하자.
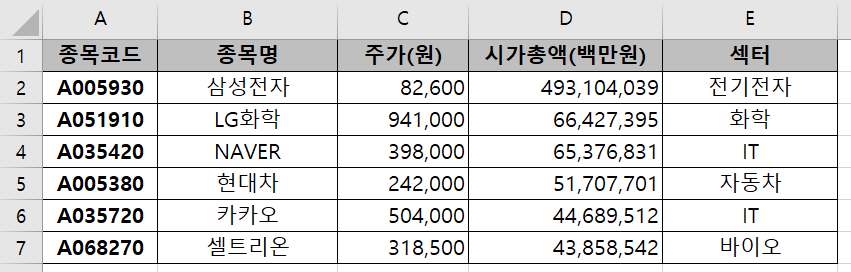 |
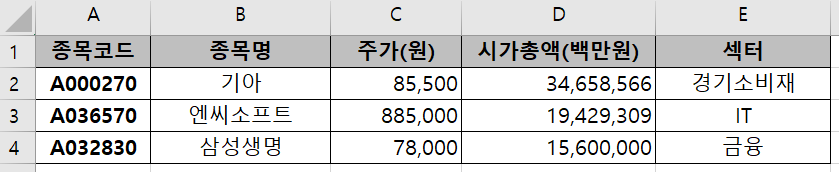 |
|---|---|
| 1일차 자료(다운로드) | 2일차 자료(다운로드) |
 |
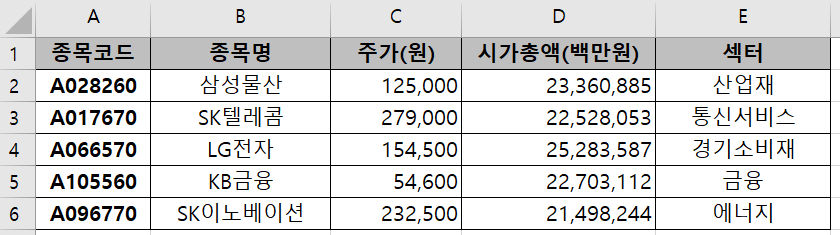 |
|---|---|
| 3일차 자료(다운로드) | 4일차 자료(다운로드) |
위에서 실습했던 내용을 아래와 같이 함수로 만들어 호출해보자.
def automate_excel(file_name):
bk = xw.Book(file_name)
sh = bk.sheets(1)
df = sh['A1:E7'].options(pd.DataFrame).value
return df
df_auto = automate_excel('주식_종목_리스트2.xlsx')
df_auto
| 종목명 | 주가(원) | 시가총액(백만원) | 섹터 | |
|---|---|---|---|---|
| 종목코드 | ||||
| A000270 | 기아 | 85500.0 | 34658566.0 | 경기소비재 |
| A036570 | 엔씨소프트 | 885000.0 | 19429309.0 | IT |
| A032830 | 삼성생명 | 78000.0 | 15600000.0 | 금융 |
| NaN | None | NaN | NaN | None |
| NaN | None | NaN | NaN | None |
| NaN | None | NaN | NaN | None |
엑셀파일명을 인수로 입력하면 A1:E7 범위 내의 표를 데이터프레임 객체로 변환해주는 함수다. 문제는 2일차부터는
표의 범위가 계속 달라지기 때문에 저대로는 함수를 사용할 수가 없다는 것이다.
여기서 options 메서드의 expand 매개변수를 활용하면 매일 변동하는 표의 범위를 자동으로 인식할 수 있다.
expand의 인수로는 ‘down’, ‘right’, ‘table’이 들어갈 수 있다. 이는 미리 설정된
Range 객체의 범위를 아래쪽(‘down’) 또는 오른쪽(‘right’), 혹은 양쪽 모두(‘table’)로 확장하는 기능이다. 아래의
예시 코드에서 df1 ~ df4 는 모두 같은 표를 가리킨다.
df1 = sh1['A1:E7'].options(pd.DataFrame).value
df2 = sh1['A1:E1'].options(pd.DataFrame, expand='down')
df3 = sh1['A1:A7'].options(pd.DataFrame, expand='right')
df4 = sh1['A1'].options(pd.DataFrame, expand='table')
두번째 줄의 코드를 해석해보면, 1) 엑셀 상에서 A1:E1에 해당하는 범위를 선택하고 2) Ctrl + Shift + 방향키 ↓를 눌러서
선택 범위를 확장한 다음 3) 확장된 범위 내의 자료값을 데이터프레임으로 불러온다는 의미다. 세번째 줄은 방향키 →, 네번째 줄은 방향키 ↓ 과 방향키 →를
연속으로 누른 경우라고 보면 된다.
앞에서 매일 컬럼명은 동일하나 종목의 종류와 수만 바뀐다고 가정했으므로, 자동화 함수를 다음과 같이 수정하면 어떤 날짜에도 사용가능하게 된다.
def automate_excel(file_name):
bk = xw.Book(file_name)
sh = bk.sheets(1)
df = sh['A1'].options(pd.DataFrame, expand='table').value
# 또는 sh['A1:E1'].options(pd.DataFrame, expand='down').value
return df
df_auto = automate_excel('주식_종목_리스트.xlsx')
df_auto2 = automate_excel('주식_종목_리스트2.xlsx')
df_auto3 = automate_excel('주식_종목_리스트3.xlsx')
df_auto4 = automate_excel('주식_종목_리스트4.xlsx')
댓글남기기